
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Today
- Total
- activation function
- AdaGrad
- adaptive learning rate
- arithmetic reasoning
- Attention is all you need
- attention mechanism
- auto encoder
- Back Propagation Trough Time
- Backpropagation
- Bayes Theorem
- BCE
- Bert
- Bidirectional Encoder Representation from Transformer
- Binary classification
- BPTT
- Chain-of-Thought
- CNN
- commonsense reasoning
- Computer Vision
- Confusion Matrix
- convolutional neural network
- Cot
- cot reasoning
- counting
- Cross Entropy Loss
- deep learning
- degradation
- Dimension Reduction
- Few-shot
- fine-tuning
데이터 분석 일지
[Paper Review] COT: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 본문
[Paper Review] COT: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
-ˋˏ ♡ ˎˊ- 2024. 5. 27. 21:31arithmetic, commonsense reasoning, simbolic reasoning과 같이 단순한 모델의 scaling up만으로 성능이 향상되지 않는 task들을 잘 수행하기 위해 본 논문은 Chain-of-Thought를 제시한다. Chain-of-Thought는 natural language task의 결과를 도출하기 위한 추론 단계를 의미한다.
1. Introduction
당시까지는 모델을 scaling up하는 것만으로도 task 수행 능력이 향상하였다. 하지만 단순 예측에서 끝나는 것이 아니라 단어의 의미를 이해하고 추론해야 하는 task들은 단순 scaling up에도 충분한 성능 향상이 일어나지 않았다. 본 논문은 이런 task들로 artihmetic, commonsense reasoning, simbolic reasoning을 설명한다.
이러한 task를 수행하기 위해서는 reasoning ability가 필요하다. 그렇다면 LLM에서 추론 능력을 발휘하게 하기 위한 방법이 무엇이 있을까? 본 논문에서는 rationale과 few-shot, 두 가지 idea를 제안한다. rationale은 결정이나 판단의 근거나 이유를 의미한다. few-shot은 fine-tuning 없이, 즉 pre-training 후 gradient update 없이, 몇 가지 단순한 input-output example과 task description을 가지고 task를 수행하는 것을 의미한다.
하지만 이런 두 방법에도 주요 한계점이 존재한다. 먼저 rationale의 한계점은 비용과 복잡성이다. rationale은 결과의 근거이기 때문에 단순한 input-output pair가 아니라, output의 근거까지 필요하다. 또, few-shot의 한계점은 reasoning task의 성능이 좋지 않고, model의 scale up에도 상당한 향상이 나타나지 않는다는 것이다. 본 논문에서는 이 두 가지 방법의 한계를 보완하면서 강점을 합치고자 한다.
few-shot의 prompt는 <input, COT, output>으로 구성된다. 본 논문에서는 COT의 개념을 series of intermediate natrual language reasoning steps that lead to the final output이라고 설명한다. Figure 1과 같이 prompt를 사용하게 된다.

2. Chain-of-Thought
Chain-of-Thought은 답을 얻기 전 추론 과정을 few-shot을 통해 모델이 인지하게 하고, 추론을 수행하도록 하는 방식이다. CoT가 가지는 매력적인 특성을 논문에서는 4가지로 설명한다.
- intermediate steps: 여러 단계로 나누어 문제를 해결하도록 한다.
- interpretable window: 모델이 문제를 어떻게 풀어나가는지 알 수 있고, 이를 통해 틀렸다면 틀린 부분이 무엇인지 확인할 수 있다.
- solve reasoning problem: 추론 문제를 풀 수 있다.
- readily elicit the reasoning ability: 추론 능력을 쉽고 단순하게 이끌어낼 수 있다.
본 논문에서는 arithmetic reasoning, commonsense reasoning, simbolic reasoning으로 추론 문제를 나누어 수행한다.
3. Arithmetic Reasoning
3. 1. Experiments Set up
- Benchmarks: GSM8K, SVAMP, ASDiv, AQuA, MAWPS
- LM: GPT-3, LaMDA, PaLM, UL2 20B, Codex
- CoT prompting:

3. 2. Results
본 논문은 결과를 통해 세 가지 insight를 얻는다.
- ~100B model에겐 효과 크지 않음 (비논리적인 CoT)
- 복잡한 문제일 수록 performance gain 증가
- GPT-3 175B, PaLM 540B with CoT >>> task-specific fine-tuned model with labeled training data

3. 3. Appendix A
본 논문에서는 작은 모델보다 큰 모델에서 더 성능이 좋은 것을 결과를 통해 알게 되었다. 이에 따라 추가적으로 62B PaLM 모델이 가진 error가 무엇이고, 540B PaLM 모델은 어떻게 그 error를 해결하는지 분석한다.
논문은 62B PaLM이 가지는 error를 세 가지 카테고리로 분류한다. 이는 각각 semantic understanding, one step missing, other error다. other error에는 hallucinations, repetitive outputs, and symbol mapping errors가 포함되어 있다. (Figure 3 참고)
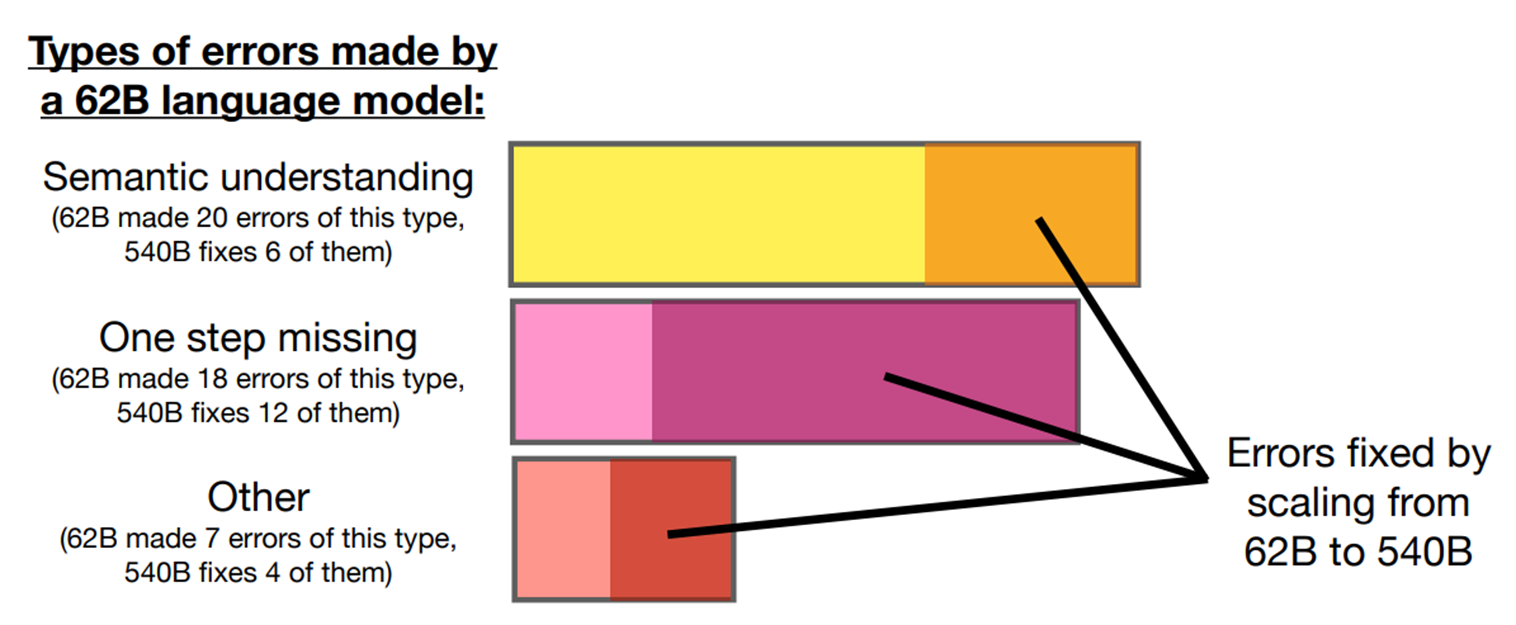
이러한 error를 540B PaLM에서는 아래의 그림과 같이 수정하였다.

3. 4. Appendix D
본 논문은 Chain-of-Thought의 error에 대해 더 자세히 알아보기 위해, LaMDA 137B로 GSM8K를 수행할 때의 정답 50개, 오답 50개를 분석하였다. 정답 50개의 경우 우연히 정답과 일치한 경우 제외하고는 모두 정답이었다. 50개의 오답 중 46%는 사소한 calculator error, symbol mapping error, one step missing error였지만, 54%는 주요 error인 semantic understanding과 coherence를 포함한다. Table 1은 calculator error, symbol mapping error, one step missing error, Table 2은 주요 error의 예시를 보여준다.


3. 5. Ablation Study
이 section에서는 CoT가 어떠한 조건에 있어서 수행 능력이 좋은지, 아니면 CoT 자체로 수행 능력이 좋은지를 판별하기 위해 prompting에 조건을 두어 실험을 수행한다. 조건은 각각 equation only, variable compute only, chain-of-thought after answer로 나누어 진행한다.
Equation only
CoT는 방정식을 풀며 task를 수행한다. 따라서 방정식만 사용하여 별다른 해석 없이 CoT를 사용하도록 했을 때의 결과를 보고자 한다. GSM8K는 직역해서 natural language reasoning 단계 없이 방정식으로 만들기에 질문의 의미가 너무 어렵다. 그래서 standard prompting에 비해 성능이 향상되지 않았다. 1-2 steps로 이루어진 dataset(SVAMP, MAWPS)에서는 성능이 향상하는 것을 볼 수 있다.

Variable compute only
CoT는 여러 단계, 즉 여러 문장에 거쳐 task를 수행한다. 따라서 정해진 최소한의 단계만 사용하여서 CoT를 수행하고자 한다. 이를 조건화하기 위해 문제를 해결하기 위해 필요한 방정식 수와 마침표 개수를 동일하게 출력하도록 하였다. 결과는 딱히 성능 향상은 없었다. 이에 따라 추론할 시간을 더 준다는 것은 CoT가 성능이 우수한 이유가 아니다.
Chain-of-thought after answer
few-shot에서 CoT를 거친 후에 답을 맞추는 식으로 prompting한다. 이를 통해 pre-training때 수집된 지식을 더욱 잘 활용하게 한다. 추론하고 답을 내는 과정에서 이 추론 부분이 중요한지 보기 위해 CoT를 답을 맞춘 다음 추론하게 하였다. 결론적으로 성능 향상은 없었다. 이에 따라 pre-training 지식을 활용해서 답을 얻어내는 것이 맞다는 것을 증명한다.

3. 4. Robustness of Chain-of-Thought
특정 prompting에 따르지 않고, 어떤 prompting이든 CoT reasoning 방식이라면 추론 능력이 우수한지를 보기 위한 실험을 수행한다. 이를 실험하기 위해 기존 prompt를 작성한 작성자 A 이외의 작성자 B와 C가 각각 prompt를 작성하도록 하였다. Table 4에 나타난 answer가 각각 작성자 B와 C의 prompt이다.

또, GSM8K에서 랜덤으로 exemplars 10개 추출한 dataset인 알파, 베타, 감마를 사용하여 실험을 수행하였다. 하지만 실험을 위해 추가된 모든 조건이 standard prompting보다 성능이 훨씬 우수하였고, 작성자 A의 prompting 성능과 비슷하였다. 이는 조건에 따라 성능 변화 없고, CoT 자체로 성능이 좋음을 증명한다.

4. Commonsense Reasoning
Benchmarks
- CSQA: 복잡한 semantic 포함하는 세상 관련 일반 상식
- StrategyQA: 질문에 답할 때 multi-hop strategy 요구됨
- Date: BIG-bench 중 하나 / 주어진 context가 설명하는 날짜
- Sports: BIG-bench 중 하나 / sports와 관련된 문장이 가능한 문장인지 아닌지
- SayCan: 로봇이 할 행동을 설명하고 지시하는 단어 mapping
Prompts

Results
PaLM의 scaling up model에서 standard prompting보다 CoT prompting이 모두 성능이 좋은 것을 볼 수 있다. 540B PaLM에서 특히 확연한 차이를 볼 수 있다. StrategyQA에서는 이전 supervised SOTA도 능가(75.6% vs 69.4%)하였고, Sports에서는 Human ability도 능가(95.4% vs 84%)하였다.


5. Simbolic Reasoning
Symbolic reasoning은 사람한텐 쉽지만 LM한텐 잠재적으로 어려운 task이다. CoT는 standard prompting으로는 어려웠던 symbolic reasoning task를 수행하고, length generalization도 잘하기 때문에 few-shot examplar에서 봤던 것보다 더 많은 단계, 즉 OOD를 요구해도 잘 수행한다.
Task
- Last letter concatenation: first letter concat보다 어려움(first letter concat은 CoT 없이도 잘 수행) / name census data에서 top 1000개 first name과 last name 조합해서 example로 사용
- Coin flip: flip or don't flip 2진 question

이전 실험 setup과 동일하게 CoT 직접 작성한다. 다른 점은 test set을 in-domain과 out-of-domain(OOD)로 나누어 실험 수행한다.
- in-domain: few-shot에서 해결하는 단계와 같은 단계 수로 구성 (2 steps)
- out-of-domain: few-shot에서 해결하는 단계보다 더 많은 단계 수행 필요한 task (3-4 steps)
Results
PaLM 540B은 거의 100% 해결율을 보인다. 100B 이상 모델에서만 ood 수행 가능하였고, 특히 ood에서는 standard prompting가 보통 수행하지 못하였다. 모든 조건에서 in-domain보다 성능 떨어지는 ood를 확인할 수 있다. 따라서 LM이 클수록 length generalization 잘한다는 의미가 된다.


6. Discussion
본 논문에서는 LLM에서 multi-step reasoning ability를 이끌어내는 단순한 매카니즘인 CoT를 탐구하였다.
먼저 arithmetic reasoning에서 큰 격차를 벌리는 우수한 성능 향상을 보였고, 이 결과가 다른 조건 때문이 아니라 오직 CoT 자체 때문임을 실험을 통해 증명하였다. 다음으로 commonsense reasoning에서는 어떻게 CoT reasoning의 언어적 특성이 commmonsense reasoning을 일반적으로 가능하게 만들었는지를 강조하였다. 마지막으로 symbolic reasoning에서는 ood를 해결할 수 있음을 보여주었다.
모든 실험에서 prompting을 통해 간단하게 CoT를 구현할 수 있었고, 일반적으로 standard prompting보다 CoT가 성능 우수함을 보였다. standard prompting에서는 flat scaling curve였지만, CoT prompting에서는 dramatically increasing scaling curve를 보인다.
Limitations
총 4가지로 나누어 볼 수 있다.
- CoT가 인간의 사고 과정을 모방하긴 하지만, 신경망이 실제로 "추론"하고 있는지에 대한 답을 제공하지는 않으며, 이는 여전히 열린 질문이다.
- few-shot에서는 CoT를 통해 examplar를 수동으로 추가하는 비용이 최소화되지만, finetuning을 위한 annotation 비용은 매우 높을 수 있다. 이는 합성 데이터 생성이나 zero-shot 일반화로 극복할 수 있을 것이다.
- 올바른 추론 경로에 대한 보장이 없어서, 이는 올바른 답과 잘못된 답을 모두 초래할 수 있다. 언어 모델의 사실적 생성 능력을 개선하는 것은 향후 연구 과제로 남아 있다.
- CoT 추론이 대규모 모델에서만 나타나는 것은 현실 세계에 모델 적용에 있어 비용이 많이 든다. 작은 모델에서도 추론을 유도하는 방법을 탐구하는 추가 연구가 필요하다.



