
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Today
- Total
- activation function
- AdaGrad
- adaptive learning rate
- arithmetic reasoning
- Attention is all you need
- attention mechanism
- auto encoder
- Back Propagation Trough Time
- Backpropagation
- Bayes Theorem
- BCE
- Bert
- Bidirectional Encoder Representation from Transformer
- Binary classification
- BPTT
- Chain-of-Thought
- CNN
- commonsense reasoning
- Computer Vision
- Confusion Matrix
- convolutional neural network
- Cot
- cot reasoning
- counting
- Cross Entropy Loss
- deep learning
- degradation
- Dimension Reduction
- Few-shot
- fine-tuning
목록Lecture or Textbook Review/Deep Learning (17)
데이터 분석 일지
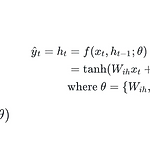 [Deep Learning] RNN (Recurrent Neural Network)
[Deep Learning] RNN (Recurrent Neural Network)
0. Foundation Concept of RNN 이전까지는 함수에 x를 입력 받으면 y를 출력하는 형식을 정의했었다. 하지만 RNN은 sequential data나 time series data를 다룰 수 있는 구조를 지닌다. RNN은 이전 time step의 출력을 입력으로 받는 특성을 가진다. 따라서 x와 이전 time step의 출력 h_(t - 1)을 입력으로 받아 현재 time step인 h_t를 출력하는 구조인 것이다. FC layer나 CNN은 이전의 출력 정보를 입력으로 받지 않고, 순서 정보를 고려하지 않는 반면에, RNN은 순서 정보나 이전 데이터에 기반한 현재 데이터의 처리를 할 수 있다. 0. 1. Sequential Data vs Time Series Data sequen..
 [Deep Learning] Computer Vision
[Deep Learning] Computer Vision
0. Introduction cumputer vision 분야에서의 딥러닝은 2012년 이미지넷의 우승으로 큰 주목을 받았다. 아래의 그림과 같이 shallow를 사용하였을 때보다 딥러닝을 사용할 수록 error가 감소하는 것을 볼 수 있다. 추가로 2012년의 AlexNet은 8개의 layer를 사용하였고, 2015년의 ResNet은 152개의 layer를 사용한 것으로 보아, 신경망이 깊어질 수록 성능이 좋아지는 것을 알 수 있다. 0. 1. Types of Computer Vision 컴퓨터 비전 안에서의 작업을 크게 네 가지로 나누어 보았다. 이는 아래와 같다. Image Classification: ImageNet, Anomaly Detections, Out of Distribution Obje..
 [Deep Learning] CNN (Convolutional Neural Network)
[Deep Learning] CNN (Convolutional Neural Network)
1. Foundation Concept of CNN 1. 1. Before Deep Learning 딥러닝에 CNN이 적용되기 전에도 convolution filter는 널리 사용되어 왔다. 하지만 traditional machine learning에서의 feature는 hand-crafted feature의 형태로 많이 사용되었다. 딥러닝에서 CNN이 적용되고 나서는, feature를 가장 적절하게 찾아내는 convolution filter를 자동적으로 구축할 수 있는 형태로 사용된다. 1. 2. Convolution Operation convolution의 동작 원리는 아래의 그림과 같다. 입력 데이터에 filter를 맞추어 element-wise multiply를 계산하고, 이를 각 칸에 맞게 ..
 [Deep Learning] Geometric Perspective
[Deep Learning] Geometric Perspective
1. Curse of Dimensionality 이번 블로그에서는 데이터의 차원이 높아짐에 따라 데이터가 희소하게 분포하게 되는 문제에 대해 설명한다. 아래의 그림에서 1차원일 때, 2차원일 때, 3차원일 때의 분포를 살펴보자. 보통 모든 점들을 학습하기 위해서 모든 구역들을 살펴보아야 하는데, 3차원의 경우에는 빈 공간이 많아져 불필요한 학습을 하게된다. 따라서 차원이 높을수록 데이터는 희소하게 분포하게 되어 학습이 어려워진다. 그렇다고 차원이 무작정적으로 낮으면 데이터를 구분하는 특징을 추출할 수 없다. 아래의 그림에서 1차원일 경우에는 같은 칸에 있는 점들을 다 같은 점이라고 생각할 것이다. 따라서 적절한 차원을 찾는 것이 필요하다. 정리하자면, 같은 정보의 데이터를 표현할 때 차원이 높아질수록..
 [Deep Learning] Probabilistic Perspective
[Deep Learning] Probabilistic Perspective
0. Introduction 딥러닝의 목적은 가상의 함수를 모사하여 원하는 출력 값을 반환하는 신경망의 파라미터를 찾고자 하는 것이다. 따라서 지금까지 gradient descent, back-propagation, feature vector 등에 대해 다뤄보았다. 이 생각을 확장시켜야 한다. 세상은 확률에 기반한다. 예를 들어 아래의 그림과 같은 모호한 그림을 보았을 때, 토끼라고 인식할 확률과 오리라고 인식할 확률을 비교하여 더 높은 확률을 가지는 쪽으로 인식하게 된다. 이러한 것도 확률분포라고 할 수 있다. 지금까지는 함수를 모사하는 것이었지만 앞으로는 확률분포를 모사하도록 학습시켜야 한다. 함수를 모사하는 방법에서는 deterministic target 값을 예측했었다. 시야를 조금 더 넓혀..
 [Deep Learning] Representation Learning
[Deep Learning] Representation Learning
0. Motivation of Embeding Vectors NLP에서 단어는 categorical and discrete value의 속성을 가짐으로써 one-hot representation으로 표현한다. 하지만 이러한 one-hot representation은 sparse vector이기 때문에 실제 존재하는 단어 사이의 유사도를 표현할 수 없다. 따라서 이를 해결하기 위하여 Word2Vec를 사용하거나 DNN을 통한 차원 축소 및 dense vector 표현을 사용한다. 이를 vector embedding이라고 한다. 1. Auto Encoder auto encoder는 압축과 해제를 반복하며 특징 추출을 자동으로 학습한다. 아래의 그림과 같이 x라는 입력을 받아 x_hat을 출력할 때, x와 ..
 [Deep Learning] Regularization
[Deep Learning] Regularization
0. Overview: Overfitting 지난 블로그에서 overfitting에 대해 다룬 적이 있다. 이는 training error가 generalization error에 비해 현격히 낮아지는 현상으로, training dataset에 있는 noise까지 학습하게 되어 training dataset에서만 error가 낮아지는 것이다. 이를 해결하기 위하여 dataset을 train, valid, test의 세 가지로 나누고, 이를 각각 parameter, hyper-parameter, algorithm을 결정하는 데에 사용하였다. 1. Regularization Regularization은 overfitting을 피하기 위해서 generalization error를 낮추기 위한 또 하나의 추가..
 [Deep Learning] Classification
[Deep Learning] Classification
1. Binary Classification 이진 분류로 Logistic Regression과 같이 입력에 대해서 출력을 1 또는 0으로 출력한다. Threshold를 기준으로 1과 0을 출력하는데, 이때 threshold는 보통 0.5이고 때에 따라 달라질 수 있다. 2. Tradeoff by Thresholding 상황에 따라서 threshold를 다르게 설정할 수 있다. 예를 들어 아래의 그림과 같이 True와 False를 나타내는 확률 밀도가 있을 때 이를 나누는 기점을 True 그래프와 False 그래프의 교점으로 설정할 수 있지만, 더 보수적으로 True나 False를 설정하기 위해서는 교점을 threshold로 설정하는 것이 아니라 다른 지점을 설정해야 한다. 보수적으로 true라고 판단하..