
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- Today
- Total
- activation function
- AdaGrad
- adaptive learning rate
- arithmetic reasoning
- Attention is all you need
- attention mechanism
- auto encoder
- Back Propagation Trough Time
- Backpropagation
- Bayes Theorem
- BCE
- Bert
- Bidirectional Encoder Representation from Transformer
- Binary classification
- BPTT
- Chain-of-Thought
- CNN
- commonsense reasoning
- Computer Vision
- Confusion Matrix
- convolutional neural network
- Cot
- cot reasoning
- counting
- Cross Entropy Loss
- deep learning
- degradation
- Dimension Reduction
- Few-shot
- fine-tuning
데이터 분석 일지
[Paper Review] GPT-3: Language Models are Few-Shot Learners 본문
[Paper Review] GPT-3: Language Models are Few-Shot Learners
-ˋˏ ♡ ˎˊ- 2024. 5. 14. 21:53당시에는 큰 text corpus를 pre-train하고 task-specific한 fine-tuning을 수행하여 굉장한 성능을 보였다. task와 무관한 data로 pre-train을 수행하다 보니 많은 양의 task-specific한 data까지 필요하게 되었다. 본 논문에서는 task-specific한 fine-tuning 없이, 즉 pre-train 이후에 파라미터 업데이트 없이, 몇 가지의 sample을 가지고 model을 여러 task에 적용하는 방법인 few-shot을 사용한 GPT-3를 제시한다.
1. Introduction
당시의 연구 경향은 downstream task와 무관한 data를 사용한 pre-trained language representation을 task-specific하게 fine-tuning하는 것이었다. 이러한 구조를 기반으로 한 다양한 model들이 개발되었고, 이에 따른 성능은 좋았지만 이 구조에도 한계점이 있었다. 주요한 한계는 task-specific한 dataset과 fine-tuning이 필요하다는 것이다. 이때 task-specific한 data는 보통 1,000개에서 100,000개 정도 사용하였다. 이러한 한계 극복의 필요성은 다음과 같다.
- 새로운 task 수행 시 많은 labeled dataset 필요 => 실용적으로 비효율적
- pre-train에서 대량의 지식을 흡수하고 작은 task data 분포에 fine-tune => out-of-distribution 문제 / 성능 과대평가 / pre-train에서 한정된 지식
- 사람은 대부분 language task를 학습할 때 large supervised dataset 불필요 = 몇 가지 예제만 가지고도 수행 가능
이 한계점을 종합하면 대량의 labeled dataset이 필요하기 때문에 몇 가지 예제만 가지고도 language task를 수행할 수 있는 사람과 달리 비효율적이라는 것이다.
본 논문에서는 이러한 한계를 해결하기 위하여 meta-learning을 제안한다. meta-learning은 train 때 다양한 기술 및 패턴 인식 능력을 개발하고, inference 때 이런 능력을 원하는 task를 인식하고 이에 빠르게 적용하는데 활용하는 방식이다. GPT-2에서는 in-context learning 방식을 활용하여 pre-trained model에 task demonstration을 input으로 입력하였다. (GPT-2 논문에서는 zero-shot이라고 설명했지만 few-shot을 사용한 경우도 있어 혼란을 줄이기 위해 in-context learning이라는 용어 사용)
또 당시 NLP 경향이 모델의 size를 키우는 것이였다. 당시까지의 transformer LM의 capacity를 보면 점점 증가하는 것을 알 수 있다.
1억(GPT-1) → 3억(BERT) → 14억(GPT-2) → 80억(Megatron) → 110억(T5) → (Project Turing)
특히 in-context learning은 최대한 다양한 skill과 task 수행 능력을 모델에 저장해야 하기 때문에 이를 저장하기 위한 모델의 크기가 클수록 성능이 좋다. 본 논문에서 제시하는 GPT-3는 1750억 파라미터로 이루어져 있다.
meta learning은 Figure 1.1과 같이 inner loop와 outer loop로 구성되어있다. 여기에서 inner loop를 in-context learning이라고 한다.

in-context learning의 예제 개수에 따라서 zero-shot, one-shot, few-shot으로 나눌 수 있다. 말 그대로 zero-shot은 어떤 예제도 사용하지 않을 때, one-shot은 한 개의 예제, few-shot은 두 개 이상의 예제를 사용할 때를 의미한다.
본 논문에서는 GPT-3를 통해 in-context learning의 ability를 24개의 NLP dataset과 새로운 task로 측정한다. 여기서 새로운 task는 pre-train set에 포함되어있지 않을 것 같은 task를 의미한다. 이러한 새로운 task를 사용하여 모델의 빠른 적응력을 test한다. GPT-3로 evaluation을 수행할 때에 zero-shot, one-shot, few-shot을 사용한다. few-shot은 최대 모델의 context window에 넣을 수 있을 정도까지 길이의 예제를 포함할 수 있다. 대략 10개에서 100개의 example을 사용하고 example의 개수는 k로 표기한다. 또 zero-shot은 예제를 사용하지는 않지만 task에 대한 설명과 지시 사항은 사용한다.
간단하게 결론을 요약하자면 아래와 같다.
- Natural language prompt > No prompt
- k에 비례하여 성능 향상
- 모델의 크기가 커질 수록 in-context 정보 활용 능력 향상
2. Approach
기본 pre-training approach는 GPT-2와 동일하고 model size, dataset size, diversity length of training만 증가하였다. in-context learning의 사용도 GPT-2와 비슷하지만 GPT-3는 zero-shot, one-shot, few-shot에 대해 각각 명시하고 비교한다. 이를 통해 얼마나 많은 task-specific data에 의존하는지 확인한다. (fine-tuning, zero-shot, one-shot, few-shot에 대한 정확한 개념과 자세한 설명 및 비교는 추후 작성 예정)

2. 1. Model Architecture
GPT-2와 같은 구조(initialization, pre-normalization, reversible tokenization*)를 사용한다. 하지만 GPT-3는 Sparse Transformer와 유사하게 transformer layer에서 dense / sparse한 attention 패턴을 번갈아서 사용한다. 이로써 모든 위치와 연결된 구조를 줄이고 필요한 곳만 집중하여 연산량 및 메모리 사용을 감소시켰다.
본 논문에서는 모델 크기에 따른 성능을 측정하기 위해 Table 2. 1과 같이 8가지 크기의 모델을 학습시켰다. 노드 간 데이터 전송을 최소화하기 위하여 깊이와 너비 차원에 따라 GPU 전체에 걸쳐 모델을 분할하였다.
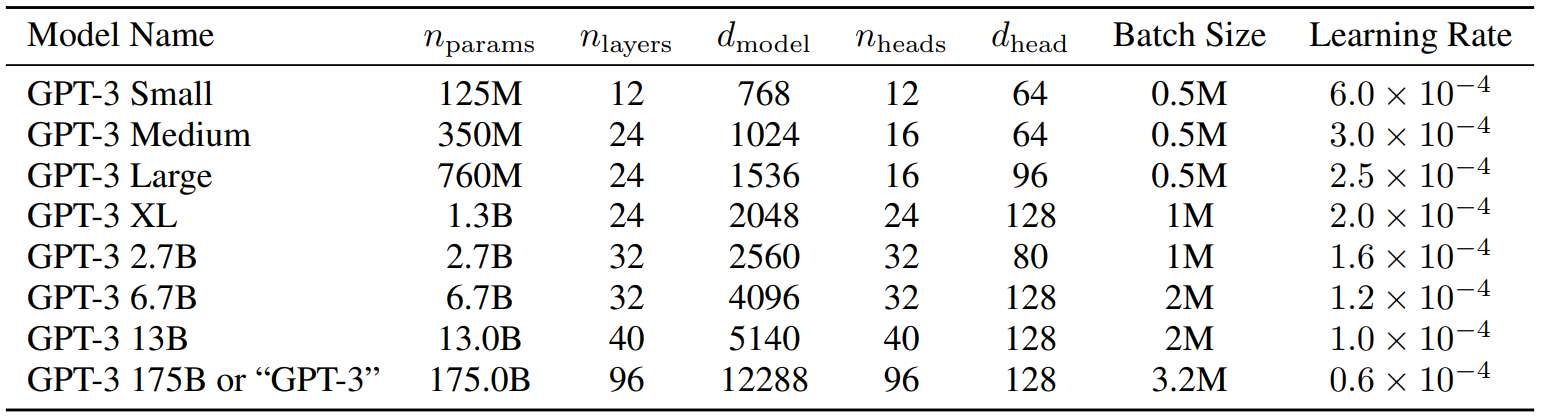
Table 2. 1의 열에서 표시된 기호의 의미는 아래와 같다.
- n_params: train 가능한 param 수
- n_layers: transformer layer 수
- d_model: 각 bottleneck layer의 unit 수 = hidden 차원 (각 bottleneck layer 당 4개의 feedfoward 존재 → d_ff = d_model × 4)
- d_head: attention head의 차원
- n_ctx: context window = 2048 token (모든 model에 적용됨)
*GPT-1에서는 word-level에서 tokenization을 수행하였지만 GPT-2와 GPT-3에서는 byte-level에서 tokenization을 수행하기 때문에 byte-level에서 다시 word-level로 복구하기 위한 reversible tokenization 사용
2. 2. Pre-training Dataset
Common Crawl dataset은 1조 개의 단어를 포함하고 있어 GPT-3를 train하기에 충분한 dataset이지만 정제되지 않은 data이기 때문에 이를 정제하기 위해 아래의 3가지 step을 거친다. (filtering Common Crawl과 fuzzy deduplication은 Appendix A에서 자세히 설명)
- high-quality corpora와 비슷한 수준으로 정제된 Common Crawl data 다운로드
- fuzzy deduplication으로 중복 데이터 제거 (valid data와의 중복 방지 / 유사성 및 근사치를 기준으로 삭제)
- high-quality reference corpora를 dataset에 추가 → data의 다양성 증가
- WebText의 확장 버전 (GPT-2에서는 45 million)
- internet based books corpora (Books 2)
- English-language Wikipedia
Common Crawl dataset은 2016년부터 2019년 사이의 data를 월별로 41 shard로 나누어서 저장하였다. 이때 저장한 data가 정제되지 않은 data로 압축된 plaintext만 45TB의 크기였다. 이를 위의 방법으로 정제하여 570GB로 축소하였다. 또 이 정제된 data는 400 billion BPE token으로 표현할 수 있다.

Table 2. 2는 사용된 dataset을 보여준다. 모든 모델에 대해 같은 training mix 비율을 사용하였다. 또한 dataset size에 비례하여 train한 것이 아니라, high-quality 정도에 비례하게 epoch 수를 결정하여 train하였다. (Common Crawl과 Books2는 high-quality가 아니기 때문에 1 미만, 다른 dataset은 2-3번 샘플)
본 논문에서는 데이터의 overlap을 지우고자 하였다. 불행하게도 filtering 과정에서 bug가 생겨서 몇몇 overlap을 걸러내지 못해지만 training 비용 때문에 다시 train하지 못 했다. 이에 따라 section 4에서 남은 overlap의 impact에 대해 설명한다.
2. 3. Pre-training Process
본 논문은 training 중에 gradient noise scale을 측정하고 이를 바탕으로 batch size를 결정하였다. 메모리 부족 없이 큰 모델을 train하기 위해서 각 행렬곱 내부와 네트워크의 각 레이어 사이에서 병렬 연산을 사용하였다. 모든 모델은 Microsoft에서 제공하는 V100 GPU의 고대역폭 cluster를 사용하였다.
2. 4. Evaluation
few-shot learning을 위해 각 task의 training set 중 k개를 random으로 가져와 conditioniong 부분으로 사용하였다. 각 예제는 1-2칸의 enter로 띄어서 분류하였다. 추가적으로 LAMBADA와 story cloze는 supervised training set이 없어서 development set에서 example을 추출하였다. Winograd는 dataset이 1개밖에 없어서 그 dataset에서 추출하였다.
k는 0부터 모델이 허락하는 context window 크기까지 설정할 수 있다. 본 논문은 모든 모델에 대해 n_ctx = 2048을 사용하기 때문에 대략 10개에서 100개 정도의 example을 사용한다. 보통 k 값은 크게 설정하지만 큰 k 값이 항상 성능이 좋은 것은 아님을 실험에서 보여준다.
몇몇 task는 example 대신 자연어로 설명하는 prompt도 사용하였고, 다지선다형 task는 context와 그에 따른 answer를 example로 보여주고 출력을 원하는 context를 보여준 후 각 option에 대한 likelihood를 계산하였다. 또, 일부 작은 dataset에 대해서는 P(completion | context) / P(completion | answer_context)를 계산하여 수행하였다. Binary calssification task는 1/0 대신 더 의미 있는 text인 True/False를 사용하여 다지선다형 task처럼 수행하였다. free-form completion task는 beam search를 사용하여 수행하였고, F1 similarity score / BLEU score / Extract Match를 사용하여 성능을 평가하였다.
3. Results

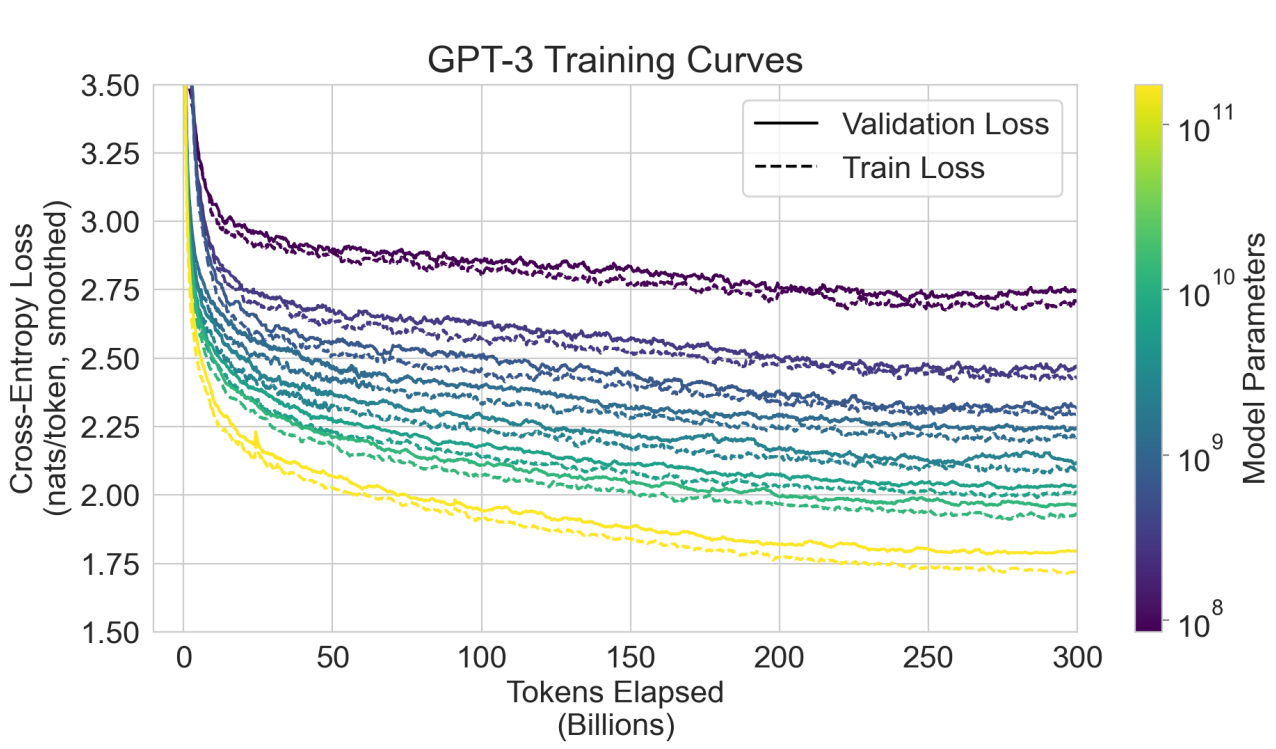
Figure 3. 1은 8개의 model과 추가적인 작은 model 6개의 연산 성능별 valid loss를 보여준다. 아래 그림을 통해 LM 성능이 효율적인 연산을 수행할 때 power-law를 따르는 것을 볼 수 있다. power-law는 데이터 규모와 LM 성능 사이의 비선형적인 관계를 의미한다. 모델의 크기가 10^2만큼 커졌을 때 power-law에서 조금 벗어나 더 향상하였지만 지속적인 power-law를 유지하는 것을 볼 수 있다. 앞으로의 실험에서는 모든 task에 대해 zero-shot, one-shot, few-shot setting을 적용하여 비교한다.
3. 1. Language Modeling, Cloze, and Completion Tasks
이 section에서는 NLP의 전통적인 task(빈칸 채우기, 문장 및 문단 완성하기, 알맞은 단어 선택하기 등)를 수행한다.
3. 1. 1. Language Modeling
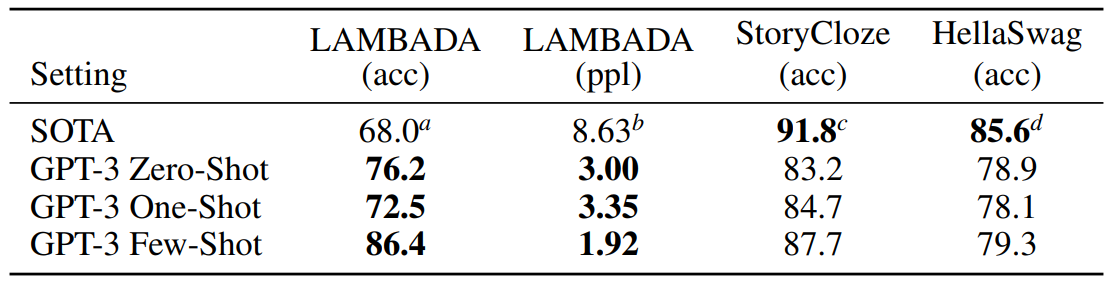
GPT-3는 4개의 Wikipedia 관련 task와 one-billion benchmark task가 모두 training set에 포함되어 있기 때문에 2 task는 생략한다. PTB data만 가지고 task를 수행한다. PTB는 명확하게 분류된 example이 없어서 one-shot과 few-shot으로는 평가하지 않는다. Table 3. 1을 보면 GPT-2의 zero-shot perplexity인 35.8보다 약 15 perplexity 감소한 20.5 perplexity로 SOTA를 달성하였다.

3. 1. 2. LAMBADA
이 task는 문장의 마지막 단어를 채워 문장을 완성하는 task로 모델의 장기의존성을 평가한다. task는 아래와 같이 수행할 수 있다.
ex) Alice was friends with Bob. Alice went to visit her friend _____. → Bob
George boght some baseball equipment, a ball, a glove, and a _____. →
최근 난이도가 높은 LAMBADA와 같은 benchmark는 모델의 크기 증가만으로는 크게 성능이 향상하지 않는다. 이전 연구에 따르면 모델의 크기를 2배 이상 증가시켰을 때 성능은 고작 1.5% 증가하였다. 이를 통해 하드웨어나 데이터 크기만 늘리는 것이 해결 방안이 아니라는 의견도 나오고 있었다. GPT-3는 기존 대비 8% 이상 성능이 향상하여 zero-shot에서 76%의 정확도를 성취하였다. 또한 few-shot에서는 model size가 커짐에 따라 강력하게 향상되어 86.%의 정확도를 성취(Figure 3. 2 참고)하였다. 하지만 one-shot에서는 zero-shot보다 성능이 저하하였다. (Table 3. 2 참고)

3. 1. 3. Hella Swag
이 task는 짧은 글이나 지시 사항을 끝맺기에 가장 알맞은 문장을 선택하는 task로 model이 어려워하지만 사람은 쉽게 해결할 수 있는 task 중 하나이다. 이때 사람의 정확도는 95.6%였고 당시 SOTA model인 ALUM(multi-task 학습 후 fine-tuning)은 정확도가 85.6%였다. GPT-3는 SOTA에는 미치지 못하는 성능을 달성하였다. (Table 3. 2 참고)
3. 1. 4. StoryCloze
이 task는 다섯 문장의 긴 글을 끝맺기에 가장 알맞은 문장을 선택하는 task이다. fine-tuned SOTA인 BERT 기반 model보다 4.1% 성능이 낮지만, 이전 zero-shot result보다 대략 10% 향상된 성능을 달성하였다. few-shot은 k = 70으로 수행하였다. (Table 3. 2 참고)
3. 2. Closed Book Question Answering
이 task는 GPT-3의 폭넓은 사실 기반 지식에 대한 질의응답 능력을 측정하기 위한 task이다. open domain QA 형태의 task에 대해 closed book test를 수행한다. 여기서 closed book은 open book과 반대되는 개념으로 외부의 content나 QA dataset fine-tuning 없이 test하는 것을 의미한다. 한 연구에서 보조 정보를 조건화하지 않아도 LLM의 성능은 괜찮다고 제시하여, 본 논문에서는 이 가설을 test하고자 GPT-3로 closed book test 수행한다. 이 section에서는 TriviaQA, WebQuestions, Natural Questions의 총 세 가지의 dataset을 사용한다. 결과는 Table 3. 3에 나타낸다.

TriviaQA는 few-shot에서 71.2%의 정확도로 SOTA를 달성한다. 또 one-shot의 경우 이전 fine-tuning/learnd retrieval mechanism을 사용한 SOTA model과 같은 성능을 보인다. (Figure 3. 3 참고)

WebQS에서는 각각의 example 수가 늘어날수록 큰 성능 향상을 보인다. few-shot으로 41.5%를 달성하였는데 이는 fine-tuned SOTA model의 성능에 근접하고, closed book에서는 SOTA이다. WebQS는 TriviaQA에 비해 zero-shot과 few-shot의 성능 차이가 크고, zero-, one-shot의 성능이 저조하다. 본 논문에서는 이러한 원인이 WebQS의 질문이나 답변 스타일이 GPT-3에게는 out-of-distribution일 것이라고 예상한다.
마지막으로 NaturalQS에서는 WebQS와 같이 각 example 수의 증가에 따라 큰 성능 향상을 보이는데 이도 같은 원인일 것이라고 설명한다. 또 TriviaQA와 WebQS보다는 성능이 저조한 것을 볼 수 있는데 이는 dataset 특성상 Wikipedia의 세부 질문을 다루어서 상당한 out-of-distribution을 야기하기 때문이라고 한다.
결론적으로 TriviaQA는 fine-tuned SOTA도 뛰어넘은 SOTA를 달성하였고, WebQs와 NQs는 fine-tuning 없이도 closed book에서 SOTA를 달성하였다.
3. 3. Translation
GPT-2에서는 용량 문제로 filtering을 거쳐 영문 data만 남긴 후 translation task를 수행하였다. 비록 성능은 낮았지만 남은 French text는 10MB임에도 불구하고 번역을 할 수 있음을 보여주었다. GPT-3는 GPT-2에 비해 100배 이상 커졌기 때문에 다른 언어를 포함할 수 있도록 data 범위도 확장되었다. GPT-3의 dataset 중 7%는 다른 언어를 포함한다. translation capability를 잘 이해하기 위해 German과 Romanian도 추가적으로 번역을 수행하였다.
현존하는 unsupervised machine translation approach는 통제된 방식으로 두 단어를 잇기 위해 back-translation과 함께 단일 언어 dataset 쌍을 combine하지만 GPT-3는 few-shot을 사용하여서 좋은 성능을 달성한다. (Table 3. 4 참고)
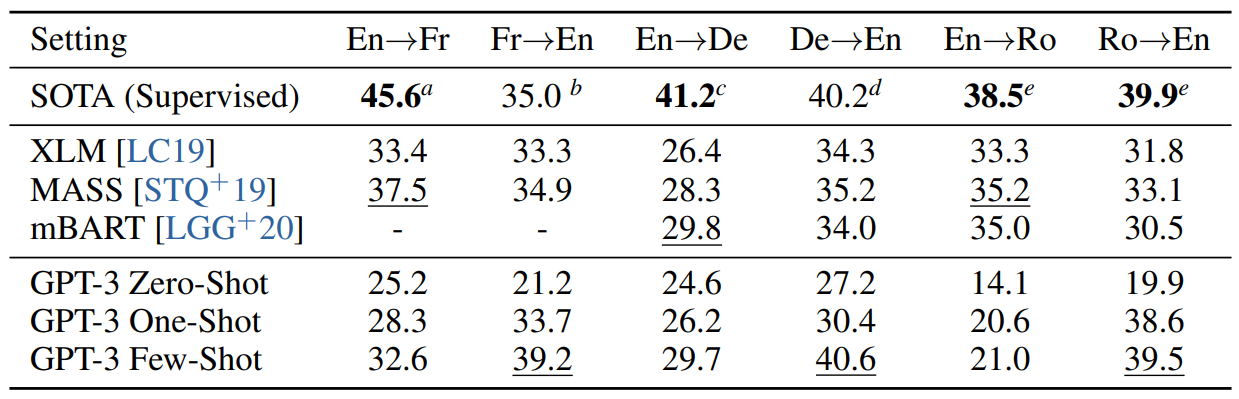
zero-shot은 NMT에 비해 성능이 모두 저하하였지만, one-shot에서는 7 BLEU 향상하였고 few-shot은 4 BLEU 향상하였다. GPT-3는 [다른 언어 → 영어]로의 번역에서는 이전 unsupervised NMT 성능을 능가하여 SOTA를 달성하였지만, 반대 방향의 번역에서는 성능이 저하하였다. 본 논문에서는 이 원인을 거의 English training set을 위해 발전된 BBPE를 사용했기 때문이라고 설명한다. Figure 3. 4를 보면 이 task도 마찬가지로 model capacity 증가에 따른 smooth trend를 보인다.

3. 4. Winograd-Style Tasks
이 task는 문법적으로 모호하지만 인간에게는 모호하지 않은 task이다. original Winograd dataset에서 최근 fine-tuned LM이 human performance와 비슷한 결과를 얻었다. 하지만 더 어려운 version인 Wiinogrande에서는 아직 human performance에 미치지 못한다.

GPT-3는 Winograd에서 명확학 in-context learning을 보여주지 않지만, Winogrande에서는 확실히 in-context learning을 수행(Figure 3. 5 참고)하였음을 알 수 있다. fine-tuned model인 RoBERTA의 성능 79%를 넘었다. Winogrande에서 human performance 성능은 94%이다.

3. 5. Common Sense Reasoning
이 section에서는 PhysicalQA, ARC(Easy version, Challenge version), Open Book QA의 세 가지 dataset으로 일반 상식을 test하는 task를 수행한다.

PhysicalQA에서는 물리 세계의 작동 원리에 대한 질의응답을 수행한다. 이 dataset에서는 zero-shot부터 few-shot까지 모두 SOTA를 달성한다. 이전 SOTA는 fine-tuned RoBERTa임에도 불구하고 SOTA를 달성하였다. 모델 크기의 증가에 따라 확연하게 성능이 향상하지는 않고(Figure 3. 6 참고), human performance보다 10% 낮은 성능을 보인다. 이 dataset에 대해 contamination issue가 있을 수도 있다고 하여 section 4에서 조사한다.

ARC는 3-9학년의 4지선다형 과학 시험 수준의 일반 상식 task이다. 이 dataset은 easy version과 challenge vesion이 존재한다. 두 vesion은 모두 각각 22% 차이, 27% 차이로 SOTA를 달성하지 못했다. 이때의 fine-tuned SOTA model은 UnifiedQA이다. (Table 3. 6 참고)
마지막으로 Open Book QA는 SOTA보다 20 point 낮지만, zero-shot부터 few-shot까지 성능을 상당히 증가시킨 것을 보아 in-context learning을 잘 활용했다고 볼 수 있다. (Table 3. 6 참고)
3. 6. Reading Comprehension
이 task는 다섯 가지의 dataset으로 모델의 문해력을 측정한다. 각각 dataset에 따른 결과는 아래와 같다. (Table 3. 7 참고)
- CoQA(free-form conversational data): human baseline과 3 point 차이로 그나마 성능이 좋다. (Figure 3. 7 참고)

- QuAC(선생-학생의 상호작용 기반 답변이 필요한 task로 구조화된 대화로 이루어진 data): ELMo baseline보다 13 point 낮은 성능을 가진다.
- DROP(질문에 대한 답을 찾기 위해 독해력/수리력 동시 요구): fine-tuned BERT baseline은 능가하였지만 human SOTA보다는 성능이 낮다.
- SQuAD 2.0: fine-tuned BERT baseline을 살짝 능가하였고, zero-shot에서 few-shot으로 10 point 향상 시켰다.
- RACE(다지선다형의 중고등학교 영어 시험): SOTA보다 45% 낮은 성능을 가진다.
이 dataset 중 RACE는 accuracy로 측정하였고 나머지 dataset은 F1 score로 측정하였다.

3. 7. SuperGLUE
NLP task에서 종합적으로 더 나은 결과를 얻고, popular 모델인 BERT와 RoBERTa와 체계적인 비교를 위한 task이다. 모든 task에 대해 few-shot learning으로 32개의 example을 사용하여 측정하였다. 각각의 example은 training set에서 랜덤으로 샘플링하였다. WSC, MultiRC를 제외하고 다 각각 다른 example을 사용하였고, 저 두 task에서는 같은 set에서 추출한 example을 사용하였다.

COPA는 주어진 문장에 대해 가장 가능성있는 원인이나 결과를 선택하는 task이다. few-shot(92.0%)과 one-shot에서 거의 SOTA를 달성하였다. SOTA보다는 2 point 낮고 leader board에서 2등이다. leader board 1등은 fine-tuned 11 billion parameter model인 T5이다. (Table 3. 8 참고)
ReCoRD는 마스크된 부분을 채우는 task이다. 90.2%의 정확도로 fine-tuned SOTA와 2.3%의 차이를 보이며 거의 SOTA를 달성하였다.
WSC는 대명사 지칭 단어를 선택하는 task이다. few-shot에서 80.1%로 비교적 좋은 성능을 계속 유지(section 3. 4 Winograd에서도 original이 88.6% 달성)하고 있다.
BoolQ / MultiRC / RTE는 각각 true/false 이진 answer / 독해 + 다지선다 / NLI task이고 모두 적당한 fine-tuned BERT와 비슷한 성능을 달성하였다.
CB는 짧은 text로 이루어진 진술에 의한 가설의 참과 거짓을 분류하는 NLI이다. few-shot에서 75.6%로 개선 및 발전의 희망을 보았다.
WiC는 주어진 단어가 2개의 다른 문장에서 동일한 의미로 사용되었는지 판별하는 task이다. few-shot에서 49.4%로 좋지 않은 성능을 얻었다. 몇몇 다른 phrasings과 formulation을 사용해 봤지만 성능이 좋지 않았다. 다음 NLI section에서 이에 대해 설명한다. (GPT-3가 one-shot, few-shot을 사용하면 특히 두 문장을 비교하는 NLI task에서 좋은 성능을 성취하지 못한 이유 설명)
이런 결과에도 불구하고 GPT-3는 8개 task 중 4개의 task는 fine-tuned BERT Large의 성능을 능가하였고 2개의 task는 SOTA(T5)와 근접하였다. Figure 3. 8을 통해 model size와 k의 증가에 따른 성능 향상을 볼 수 있다. 이는 in-context learning을 활용한다는 증거가 된다. k는 최대 32까지 사용하였는데 이 이후는 context window를 초과하기 때문이다. 또한 전반적인 SuperGLUE score에서 8개의 예시만 가지고도 fine-tuned BERT Large의 성능을 능가함을 볼 수 있다.

3. 8. NLI
NLI는 두 문장 간의 관계 이해 능력을 평가하는 task이다. 보통 2-3 class classification으로 이루어져 포함, 모순, 중립 등을 분류하는 구조이다. SuperGLUE의 NLI task인 RTE(2진 분류)는 GPT-3의 제일 큰 version에서만 chance-level(50%)을 능가한다.
ANLI로도 NLI 능력을 평가하는데 이 task는 세 개의 round로 구성되어 있으며 각 round마다 난이도가 올라간다. 역시나 GPT-3보다 작은 model들은, 심지어 few-shot에서도 chance-level보다 성능이 낮았다. 이로써 NLI는 역시나 여전히 LM에게 어려운 task임을 알 수 있다.

3. 9. Synthetic and Qualitative Tasks
간단한 계산 추론이나 특이한 task에도 적용할 수 있음을 보여주기 위한 task들을 평가한다. 여기서 특이한 task는 traning set에 없던 새로운 pattern을 가지는 task를 의미한다.
3. 9. 1. Arithmetic
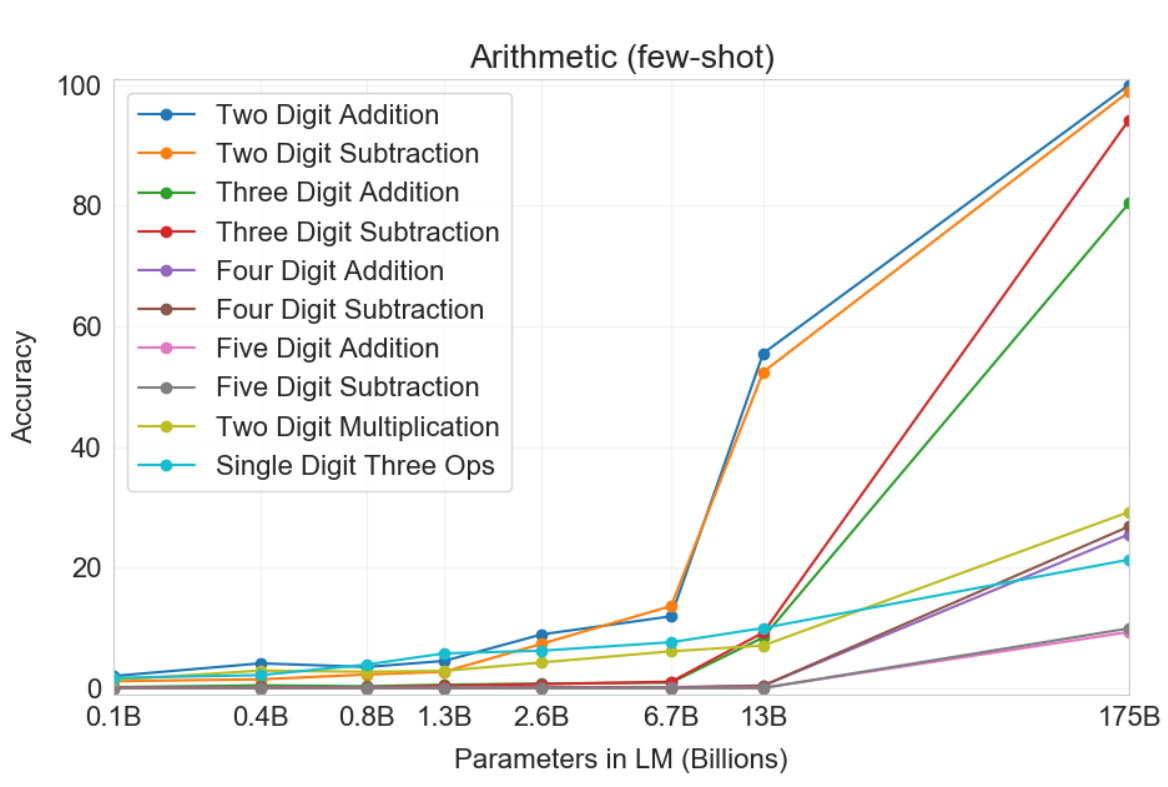
이 task에서는 수리력을 평가한다. 2D+, 2D-, 3D+, 3D-, 4D+, 4D-, 5D+, 5D-, 2DX, 1DC의 10개의 task를 수행한다. 각 task의 숫자는 digit 수를 의미하고, 그 뒤의 기호는 연산 기호를 의미한다. 추가적으로 1DC는 한 자릿수 세 개를 가지고 연산하는 것을 의미한다. 각 task마다 2,000개의 random instace를 만들어 수행하였다.

few-shot에서 2D+, 2D-, 3D+, 3D-는 80~100%의 정확도를 달성하였고, 4D+, 4D-는 25~26%, 5D+, 5D-는 9~10%의 정확도를 달성하였다. 2DX는 29.2%, 1DC는 21.3%의 정확도를 달성하였다. 결과적으로 digit의 수가 낮을수록 정확도는 향상되었다. GPT-3 다음으로 작은 model인 13B에서는 2D+와 2D-만 50%의 정확도를 달성하였고 나머지 task는 10%보다 낮은 정확도를 달성하였다. (GPT-3보다 작은 model들은 다 좋지 않은 성능을 가짐)
또한 one-shot과 zero-shot은 few-shot보다 성능이 좋지 않았다. 이를 통해 model이 이 task가 어떤 task인지를 인지하고 이해하는 것이 정확한 연산을 하는데에 중요한 역할을 한다고 할 수 있다.
모델이 pre-train set에 있던 연산을 momorizing하는지 확인하기 위해 3D+, 3D-의 test set과 pre-train set을 비교하였다. 3D+에서는 2,000개 중 17개 일치하였고, 3D-에서는 2,000개 중 2개 일치하였다. 따라서 memorize하기 보다 관련 연산을 수행하려 했다는 것을 알 수 있다. 또 틀린 답을 확인하였더니 대부분 '1'을 빼먹어서 틀리는 경우였다.
3. 9. 2. Word Scrambling and Manipulation Tasks
5개의 character manipulation을 통하여 모델의 성능을 평가한다. 각각의 manipulation은 다음과 같다.
- Cycle letters in word(CL): eapplepin = pineapple
- Anagrams of all but first and last characters(A1): ppielanpe = pineapple
- Anagrams of all but first and last 2 characters(A2): pipepanle = pineapple
- Random insertion in word(R1): p!i!n e.a?p!p/l e = pineapple
- Reversed words(RW): elppaenip = pineapple
각 task 당 10,000개의 example을 생성하였고, 이 example은 natural language corpus data에서 4~15 character 중에 가장 많이 나온 단어 순으로 추출하였다. 또, 모든 task의 k = 100으로 설정하였다.
Table 3. 10에서 나타나듯이 few-shot에서는 R1, CL, A2, A1, RW 순서대로 성능이 좋았고, one-shot에서는 모든 task가 few-shot보다 반 이상 저하한 성능을 보였으며, zero-shot에서는 모든 task를 거의 수행하지 못했다. 또한 RW task는 모든 setting 및 model에서 0%의 성능을 보였다. 이런 인공적인 manipulation은 pre-training set에서 보기 드물기 때문이라고 설명한다.
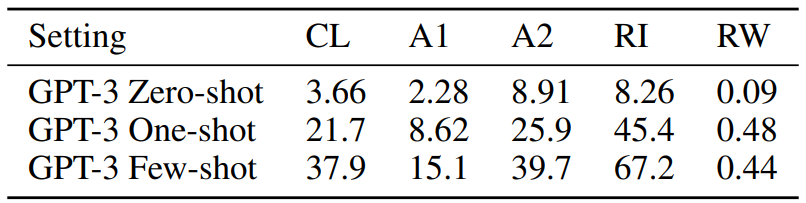
Figure 3. 11과 같이 model size에 따라 smooth한 성능 향상을 보였다.
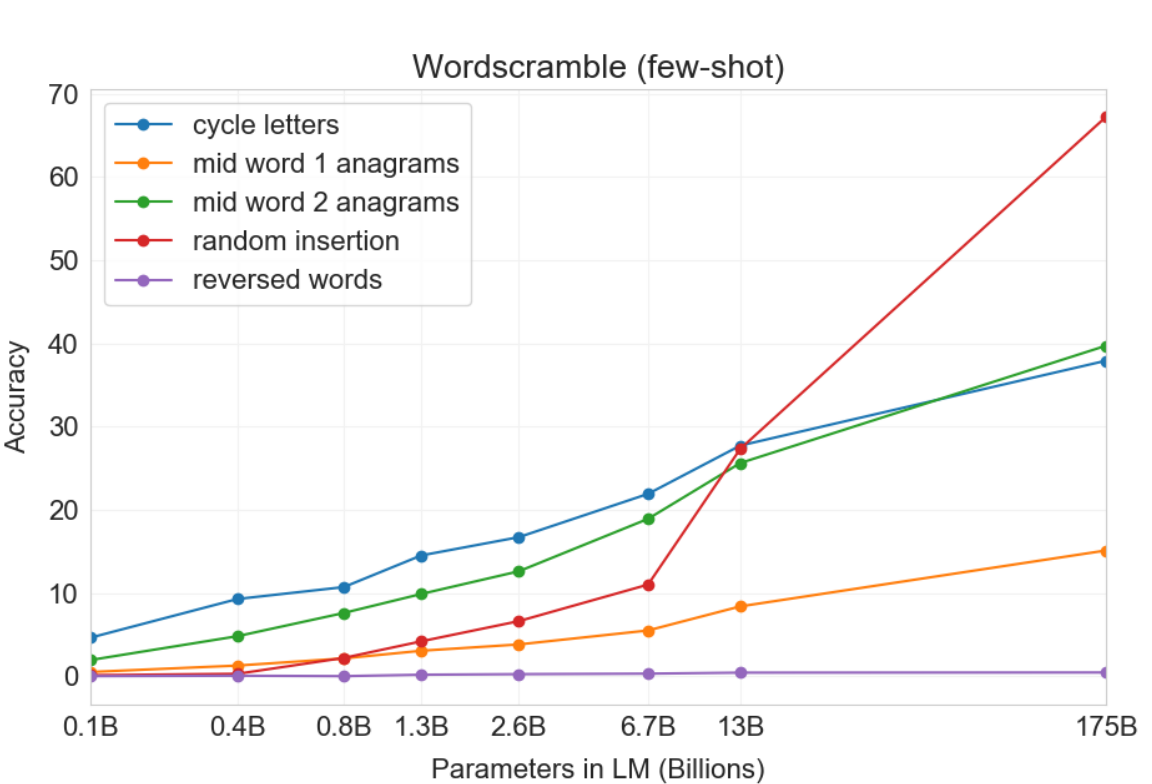
Figure 3. 12는 R1의 k에 따른 in-context learning curve를 보인다. 이를 통해 큰 모델일수록 in-context information(examples + description)을사용하여 성능이 향상되는 것을 볼 수 있다.
GPT-3에서 사용하는 BPE는 각 token에 약 0.7개의 단어가 포함되도록 한다. 이 task는 문자 수준의 구조를 조작하고 단어의 하위구조(BPE token)를 이해하는 능력이 필요하다. 또, 단순한 패턴 매칭 및 계산 이상의 수준을 필요로 한다.
3. 9. 3. SAT Analogies
이 task는 2005년 이전의 SAT의 한 section으로 원래 단어 쌍 관계와 같은 관계 단어 쌍을 선택하는 다지선다형 task이다. GPT-3의 일반적인 text 분포에 비해 특이한 task 수행 능력을 평가하기 위한 task이다. 이 task의 예로는 다음과 같다.
ex) original: Cat is to kitten / choice: A is to B, C is to D, ..., Dog is to puppy / answer: Dog is to puppy
이 task는 논리적 추론 능력과 어휘력 및 두 단어 간의 관계 이해 능력을 요구한다. GPT-3로 zero-shot, one-shot, few-shot의 성능은 각각 53.7%, 59.1%, 65.2%을 달성하였다. 대학 지원자의 평균 정확도는 57%이고, chance-level이 20%인 것에 비해 좋은 성능을 성취하였다.

Figure 3. 13을 통하여 모델 size가 커질 수록 성능이 커지는 것을 볼 수 있고(13B → 175B: 10% 향상), 작은 모델은 in-context information을 활용하지 않는 것을 볼 수 있다.
3. 9. 4. News Article Genreation
이전의 생성형 LM 연구에서는 인간이 작성한 뉴스 기사의 첫 문장을 조건으로 하여 가짜 뉴스 기사를 생성하는 test를 통해 LM의 생성력을 평가하였다. GPT-3에서 사용한 dataset에는 뉴스 기사에 대한 가중치가 낮기 때문에 모델을 few-shot으로 뉴스 기사를 example로 제공하였다.
모델의 성능은 80명의 미국 기반 참가자들이 모델이 쓴 기사인지 인간이 쓴 기사인지를 구별하는 것으로 평가하였다. newser.com에서 25개의 기사 제목과 부제목을 임의로 추출하여 125M부터 175B까지 4개의 모델이 이에 따른 기사 내용을 생성하는 형식으로 수행하였다. 추출한 기사의 평균 단어 수는 215 단어이고, 모델이 생성한 기사의 평균 단어 수는 200 단어이다. 아래는 80평의 미국 기반 참가자들이 평가한 평가 지표이다:
- very likely written by human
- more likely written by human
- I don't know
- more likey written by a machine
- very likely written by a machine
공정한 평가를 위하여 모든 model은 pre-training과 prompt와 output에서 같은 context 조건을 사용하였다. 또, 참가자의 일관성을 조사하기 위해 추가적인 실험을 진행하였다. 일부러 성능이 좋지 않은 model인 control model을 사용하여 참가자들이 제대로 평가를 하는지 확인하였다. control model은 160M parameter model이고 context 없이 사용하였으며 output의 무작위성을 증가시켰다.



Figure 3. 15와 Figure 3. 16은 GPT-3가 생성한 뉴스 기사로, 전자는 12%의 정확도로 GPT-3가 썼다고 분류되었고 후자는 61%의 정확도로 GPT-3가 썼다고 분류된 뉴스 기사이다.
결론적으로 control model이 만든 bad quality 기사를 판별하는 인간의 평균 정확도는 86%였으며, 본 논문은 이 정확도는 무작위로 판별하는 chance-level(50%) 이상이므로 어느 정도 일관성을 보장하였다. 175B model가 생성한 기사에 대해서는 인간의 정확도가 52%를 달성하였고, 이는 chance-level과 비슷하므로 모델의 크기가 커질 수록 인간의 판별력은 낮아짐을 확인(Figure 3. 14 참고)하였다. Appendix E에 따르면 모델의 크기가 커질 수록 참가자의 고민 시간 또한 증가하였다고 한다.

더 긴 내용으로 써진 기사는 인간이 더 분류를 잘한다는 연구 결과가 있었다. 이를 기반으로 추가적인 실험을 수행한다. 이때의 실제 인간이 작성한 기사의 평균 단어 수는 569 단어였으며, 모델이 생성한 기사의 평균 단어 수는 498 단어로 이전 실험보다 298 단어 증가하였다. 이 경우의 결과도 control model에서 88%, GPT-3에서 52%로 비슷한 결과를 얻었다.

3. 9. 5. Learning and Using Novel Words
이 section에서는 새로운 단어를 배우고 사용하는 능력을 평가하고자 하였다. 예를 들어 단어의 정의를 한 번만 보고 문장에서 사용하는 능력이나 문장에서 한 번의 단어 사용으로 단어의 정의를 추론하는 능력 등을 평가한다. 이런 능력을 평가하기 위해 세상에 존재하지 않는 단어와 정의를 만들어 사용하였다. 또, few-shot과 one-shot을 융합하여 사용하였다. 총 6개의 example을 제시하는데 첫 번째는 사람이 만든 단어와 그 정의 그리고 그 단어를 사용한 문장을 제시한다. 다음 example들은 모두 단어와 그 단어의 정의만 설명한다.
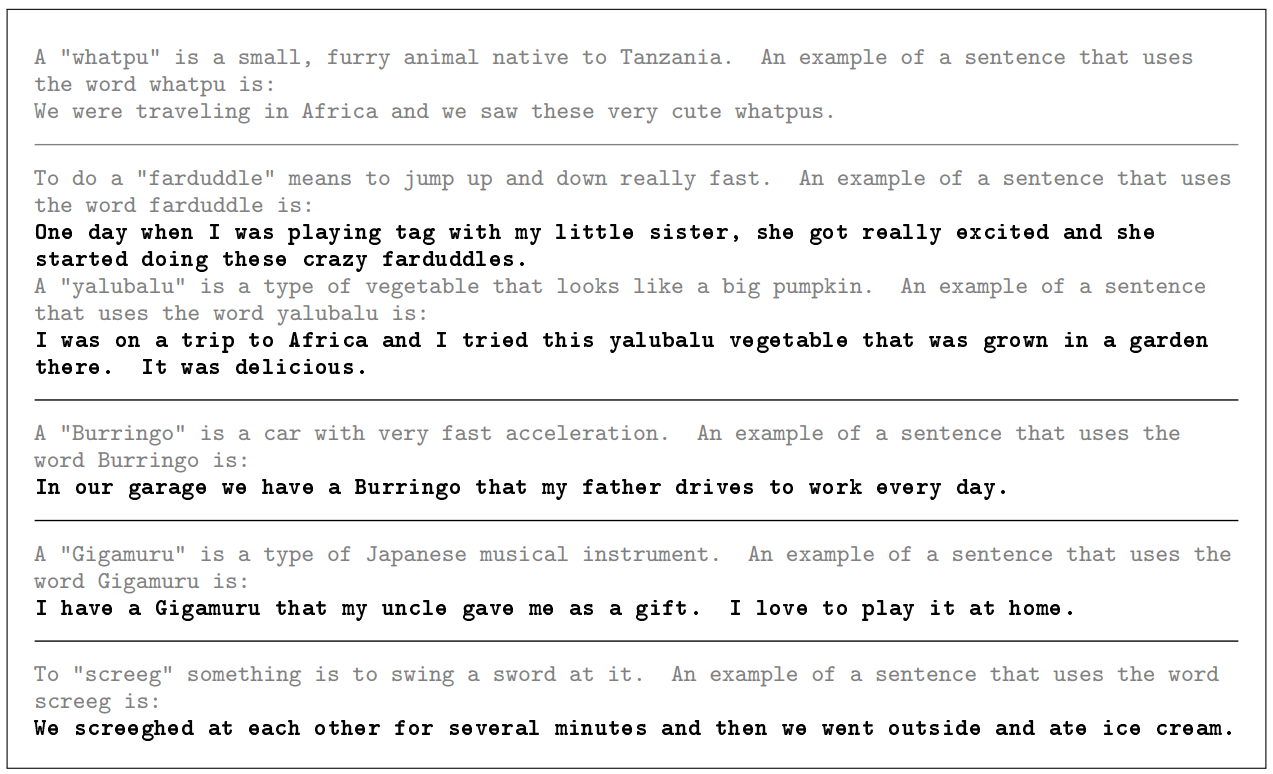
결론적으로 뒤에 s를 붙인다던지 등의 문법적으로는 사용 가능하게끔 문장을 생성하고, 능숙한 단어 사용을 보였. 하지만 마지막 example이었던 "screeg"에서 살짝 어색한 사용을 보였다. (칼을 휘두르다는 뜻으로 설명하였지만, 문장을 해석하면 칼을 휘두른 후 같이 밖으로 나갔다는 뜻이 됨)
3. 9. 6. Correcting English Grammar
이 section에서는 few-shot 능력을 확인하기 위해 영어 문법 교정 task를 수행하였다. prompt는 Poor English Input: <sentence> \n Good English Output: <sentence>의 형식으로 사용하였다.

Figure 3. 18과 같이 영어 문법 교정 task에서도 좋은 성능을 보였다.
4. Measuring and Preventing Memorization of Benchmark
GPT-3의 training dataset은 인터넷에서 추출된 dataset이다. 따라서 benchmark test set의 data가 training dataset에 포함될 가능성 존재한다. 대량의 data를 pre-training하는 경우는 흔치 않기 때문에 이런 식으로 contamination을 조사하는 경우 또한 흔치 않다. 데이터의 scale이 커지고, internet에서 가져오는 만큼 효과적으로 중복을 분류하고 탐지하는 법에 대해 연구해야된다.
Common Crawl data로 언어 모델을 training하는 논문에서 평가 dataset이랑 겹치는 trainng dataset은 모두 판별하여 삭제하였고, GPT-2 같은 연구에서는 사후 overlap 분석을 수행하였다. 이런 연구들은 사실상 중복 부분이 조금밖에 없었기 때문에, 비록 overlap data 때문에 성능이 약간 향상하였어도, 비교적 긍정적인 결과를 얻었다.
GPT-3는 GPT-2보다 큰 dataset과 model size 사용하기 때문에 기존과는 다른 대처 방법이 필요하다. dataset으로 엄청난 양의 common crawl data 사용하는데 이는 contamination과 memorization 가능성 증가시키기 때문이다. Figure 4. 1에서도 나타나듯이 GPT-3의 pre-training data는 양이 많기 때문에 overfitting 일어나지 않는다. (Figure 4. 1 고) 따라서 본 논문은 contamination은 자주 일어나지만, 많은 영향을 끼치진 않을 것이라고 예상한다.
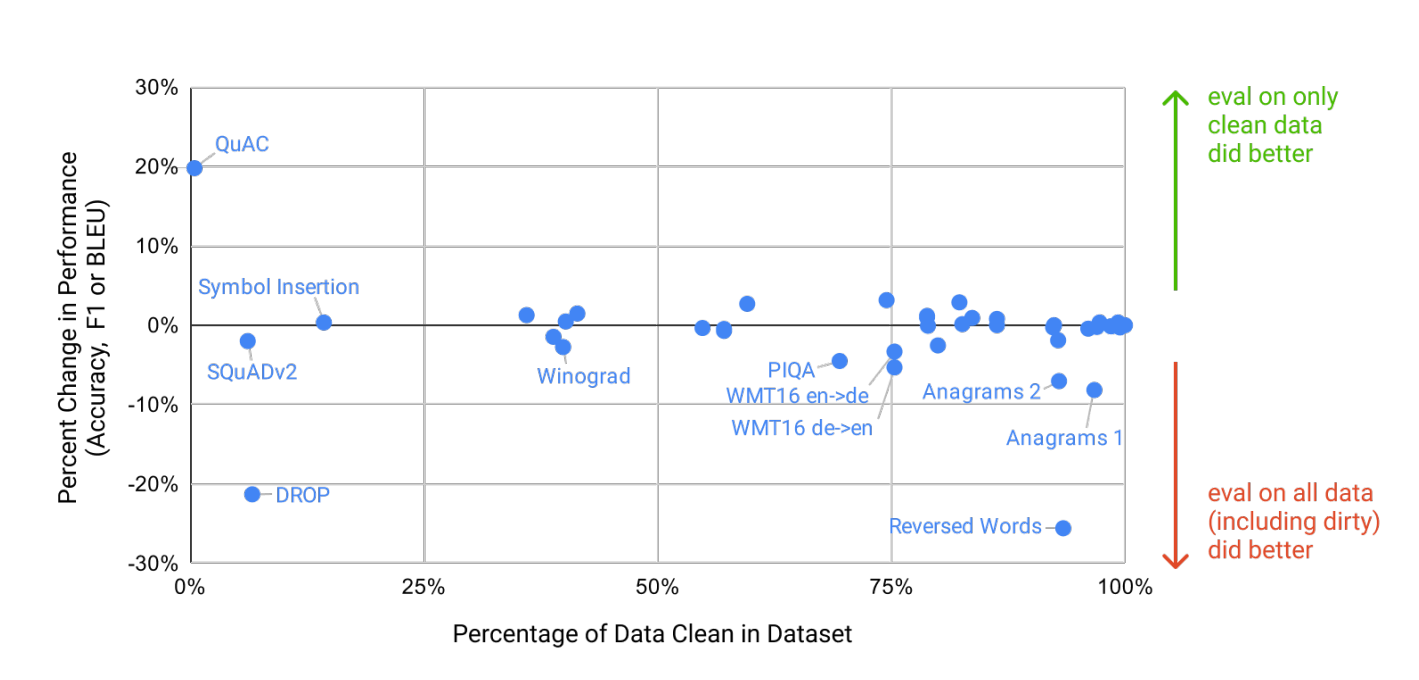
원래는 train, valid, test에 있는 모든 중복을 찾아서 지우려고 하였지만 bug로 인하여 중복된 data 중 일부만 삭제되었다. bug를 알아차렸지만 model을 train하는 비용 때문에 model을 다시 train할 수 없었다. 이를 해결하기 위해 남은 중복 data가 결과에 어떤 영향을 끼치는지 조사하기로 한다.
각각 benchmark에 대해 유출된 example들을 다 제거한 clean version을 생성하였다. 여기서 유출된 example 기준은 pre-training set에서 13-gram 이상이 overlap되었거나 애초에 모든 token이 중복인데 example이 13-gram보다 작을 경우를 의미한다. 이러한 분석을 수행하기 위한 첫 번째 목표는 보수적으로 contamination 가능성이 있다면 다 제거하여 clean subset을 만드는 것이다.
본 논문은 benchmark를 6 그룹으로 나누어 분석하고자 한다: Word Scrambling, Reading Comprehension (QuAC, SQuAD2, DROP), PIQA, Winograd, language modeling tasks (Wikitext tasks, 1BW), and German to English translation
보수적으로 분석하였기 때문에 false positive (중복이 아닌데 중복이라고 판단) 가 발생할 수 있다.
Reading Comprehension:
분석 결과 QuAC, SQuAD2, DROP에서 90% 이상이 contamination data였다. overlap 비율이 높았기 때문에 clean subset을 만들기 어려웠지만 source text만 training data에 존재하고 question/asnwer pair는 존재하지 않았다. 즉, 배경지식만 알고 있고, 특정 질문에 대한 답은 기억하지 않았다는 것이다.
German translation:
WMT16 German-English test set에 있는 example 중 25%가 contamination data였다. 이에 따른 전체 영향은 1-2 BLEU라고 한다. NMT training data의 paired sentences가 중복인 것이 아니라 뉴스 기사의 짧은 발췌로 이루어진 단일 문장만 중복이었다.
Reversed Words and Anagrams:
task 특성상 short length 때문에 구두점을 제외하고, 2-gram 필터를 사용하였다. 중복 양은 적었다고 분석하였다. 사실 symbol insertion task에서는 중복 많지만 성능에 영향 끼치지 않는 중복 단어들을 가지고 있었다. 예를 들면 kayak = kayak 같이 실제 task를 풀기 위한 dataset이 아닌 경우이다.
PIQA:
29%가 contamination data였다. 이에 따른 전체 영향은 3%라고 한다. 비록 test set이 training set 수집 기간 이후에 출시되었지만 이 dataset을 만든 사람의 웹페이지가 training set에 포함되어 있어 생각보다 높은 중복률을 보인다.
Winograd:
45%가 contamination data였다. 이에 따른 전체 영향은 2.6%라고 한다. 수동으로 계산했을 때 132 winograd schema가 training set에 포함되었지만 GPT-3가 해결하는 task와는 다른 형식으로 포함되어 있었다.
Learning modeling:
4개의 Wikipedia language modeling benchmark와 Children's Book Test dataset의 거의 전체가 포함되어 있어서 clean dataset 만들기 힘들어, Penn Tree Bank dataset만 사용하였다.
분석을 통해 중복률이 높은 dataset을 사용했을 때의 성능에 미치는 영향은 거의 zero였다는 것을 보여준다. (Figure 4. 2 참고) 보통 false positive였거나 task의 answer은 나타나지 않았기 때문이라고 설명한다.
5. Limitations
5. 1. 성능적 한계
GPT-2에 이어서 양적 및 질적으로 향상 했지만, text synthesis나 몇몇 NLP task에서 아직 한계를 보여줬다. text synthesis에서 전반적인 퀄리티는 향상했지만 긴 글에서 일관성을 잃거나, 모순적이고 비논리적인 글을 생성하며, 맥락에 맞지 않는 문장 및 단락 포함하는 등의 성능적 한계를 보여줬다. Discrete language task에서 몇 dataset(PIQA)에서는 좋은 성능을 보여줬지만 Common sense physics 부분에서 성능이 좋지 않았다. 특히 여러 문장을 비교하는 comparison task(WIC, ANLI)에서는 chance level과 one-shot 및 few-shot이 성능 비슷하게 측정되었다.
5. 2. 구조적 한계
GPT-3는 단방향 구조의 in-context learning을 사용하는데, 이는 likelihood를 샘플링하고 계산하는 것이 간단하기 때문이라고 설명한다. 이러한 구조는 양방형 구조를 사용하지 않음으로써 얻는 한계도 있다. 양방향 구조가 아니여서 성능이 저하된 task들에는 fill-in-the-blank task와 WIC(두 문장에서 같은 단어를 사용했을 때 단어 의미 비교), ANLI(가설, 전제로 이루어진 두 문장 비교), reading comprehension task(QuAC / RACE) 등이 있다.
5. 3. 근본적 한계
당시 언어 모델들은 모델 size와 data size에 대해서 scaling up을 하는 것이 트렌드였다. GPT-3의 목적함수는 모든 토큰에 동일한 가중치를 부여하여 어떤 토큰이 더 중요한지 또는 덜 중요한지 구분하지 않는다. 현재 pre-training 목적함수는 단순한 self-supervised 기반하여 단어를 예측하는 것이지만, 현실의 language task는 단순 예측과는 다르기 때문에 단순한 예측이 아닌 목적 지향적인 행동 필요하다고 설명한다.
5. 4. pre-training의 비효율성
one-shot과 few-shot을 통해 사람이 문제를 해결하는 방식을 사용하지만, 사람이 평생 보는 text의 양보다 더 많이 pre-training된다. 실질적으로 인간은 GPT-3보다 더 적은 양의 text를 보고 language task를 해결할 수 있다. 따라서 이에 대한 효율을 높여야 한다.
5. 5. 불확실성
모델이 few-shot을 통해 새로운 task를 학습하는 법을 학습하는지, pre-training 동안 이미 학습한 것인지를 알 수 없다. synthetic task의 경우에는 새롭게 학습했을 가능성이 있지만 translation task는 대부분 pre-training에서 학습했을 가능성이 있다. 사실상 사람도 이전에 학습했던 것인지 새로 학습한 것인지 확실하지 않은 경우가 있다.
5. 6. 비용의 한계
clean set으로 학습하는 과정에서 중간에 버그가 발견했음에도 불구하고 학습을 중단하지 못하였다. 그만큼 GPT-3의 훈련 비용은 비싸다는 것을 의미한다. 또한 추론시에도 적지 않은 비용이 발생한다. 실제로 GPT-3과 같이 여러 task를 해결할 수 있는 모델을 사용하기 위해서는 각각 task를 위한 구조로 distillation하는 과정이 필요하다.
5. 7. 설명 가능성
기존의 딥러닝 시스템과 같은 한계가 존재한다. 이는 black box에 대한 설명력이 부족하다는 것이다. 새로운 input에 대해 인간보다 더 큰 variance 보이고, data 자체의 bias를 해결하지 못한다. 세상에 존재하는 사회적 문제를 모델이 반영할 수 있다는 문제가 있다. 이는 다음 section에서 소개한다.
6. Broader Impacts
language model들은 사회적으로 좋은 영향을 끼친다. 예를 들어 코드 및 글 쓰기, 질문에 답하기, 문법 교정 등이 있다. 하지만 이와 반대로 사회에 끼치는 악영향 또한 존재한다. GPT-3는 작은 모델들보다 텍스트 생성의 퀄리티를 향상했고, 사람이 쓴 글 못지않게 좋은 성능을 보였지만 이런 부분에서 모델의 선영향 및 악영향을 모두 가질 수 있다. 이 section에서는 모델이 사회적으로 미치는 악영향에 대해 설명한다.
7. Conclusion
결론적으로 본 논문에서는 175B parameter를 가지는 GPT-3를 개발하였고, 많은 NLP task에서 fine-tuning 없이도 좋은 성능을 보였다. 몇몇 한계점도 존재했지만, fine-tuning 없이 few-shot, one-shot, zero-shot으로만 NLP task를 수행했다는 점에서 NLP 분야의 중요한 요소가 될 수 있음을 시사한다.
Appendix
A. Details of Common Crawl Filtering
section 2. 2.에서 언급되었 듯이, Common Crawl dataset의 퀄리티를 향상하기 위한 두 가지 방법을 더 자세히 설명한다. 이는 각각 filtering Common Crawl과 fuzzy deduplication이다.
a. 1. filtering Common Crawl
본 논문은 Common Crawl의 퀄리티 향상을 위해 낮은 퀄리티의 document는 삭제하는 자동 필터링 방법을 사용한다. raw Common Crawl에 high-quality인 original WebText를 추가하여 이 WebText data를 분류하여 분류기를 훈련하였다. 그다음 Common Crawl data에서 높은 퀄리티 순으로 data를 re-sample하였다. 분류기는 Spark’s standard tokenizer와 Hashing TF에서 제공하는 feature를 사용한 logistic regression classifier를 사용하였다. positive example로는 WebText, Wikiedia, web books corpus 등을 사용하였고, negative example로는 unfiltered Common Crawl을 사용하였다. 아래의 수식과 같이 문서의 점수와 랜덤한 Pareto 분포를 비교하여 문서를 선택한다.
$$ np.random.pareto(α) > 1 − document_score $$
위 수식이 의미하는 것은 각각 아래와 같다.
- np.random.pareto(α): 파레토 분포를 따르는 난수를 생성하는 NumPy의 함수이다. 이 분포는 오른쪽으로 꼬리가 긴 분포를 나타낸다.
- α: Pareto 분포의 형태를 결정하는 모수(parameter)이다. 이 값이 클수록 분포의 꼬리가 길어지게 된다.
- document_score: 분류기가 부여한 문서의 점수이다. 이 점수는 일반적으로 0과 1 사이의 값으로 정규화된다.
이를 토대로 위 수식을 설명하자면: 만약 파레토 분포에서 생성된 난수가 1−document_score보다 크다면, 해당 문서를 선택한다. 이 선택 기준을 만족하는 문서들을 데이터셋에 포함시킨다. 여기서 α 값은 Pareto 분포의 모양을 결정하며, 9로 선택된 것은 대부분의 높은 점수를 받은 문서들을 선택하되, 분포 밖의 일부 문서도 포함시키기 위한 것이다.
a. 2. Fuzzy Deduplication
각 데이터셋 내에서 문서의 품질을 높이고 중복을 방지하기 위해 모호하게 중복된 문서를 제거했다. 이는 Spark의 MinHashLSH 구현을 사용하여 수행되었다. MinHashLSH는 최소 해시 기법을 사용하여 유사한 문서를 찾는 데 효과적인 방법 중 하나입니다. 여기서는 10개의 해시를 사용했다. 이 작업에는 위의 분류에 사용된 것과 동일한 기능을 사용했다. 이러한 작업을 통해 데이터셋의 크기가 평균적으로 10% 감소했다.
B. Details of Model Training
모든 버전의 GPT-3를 train하기 위해서 아래와 같이 설정하였다.
- Adam: β_1 = 0.9, β_2 = 0.95, ε = 10^−8
- Gradient Clipping: 전역 gradient의 크기를 1.0으로 제한
- Learning Rate Decay: cosine decay를 사용하여 learning rate 조절 (초기 375 million token에 대해서 linear LR warmup 수행)
- Batch size: 훈련 초기에는 작은 값(32k 토큰)에서 시작하여 처음 4-12 억 토큰에 걸쳐 배치 크기를 선형적으로 증가 (모델의 크기에 따라 증가하는 기간 다름)
- Data Sampling: 훈련 동안 데이터는 치환 없이 샘플링 (모델이 데이터의 순서 기억 방지, 오버피팅 최소화)
- Weight Decay: 모든 모델은 0.1의 weight decay를 사용하여 정규화 제공
- number of context window: 어떤 모델이든 n_ctx = 2048 token
C. Details of Test Set Contamination Studies
c. 1. Initial training set filtering
본 논문은 benchmark에 등장하는 training data를 지우고자 하여, 사용되는 모든 task의 test/development set와 training data 간의 13-gram overlap을 찾아 제거하였다.
c. 2. Overlap methodology
section 4의 benchmark overlap analysis에 따르면 본 논문은 단어 개수의 변수를 나타내는 N을 사용하였다. 여기서 N은 데이터셋 내의 예시 중 단어 길이 하위 5%의 평균 길이를 나타낸다. N의 최솟값은 8, 최댓값은 13으로 설정한다. GPT-2에서는 확률적인 bloom filters를 사용하였지만, GPT-3에서는 Apache Spark 사용하여 정확한 오염 데이터를 추출하였다.
필터링하는 과정에서 bug가 일어나서 book과 같은 긴 문서들은 필터링하는 데에 실패하였다. 하지만 training과정의 비용적인 문제 때문에 다시 필터링 작업을 할 수 없었다. 따라서 몇몇 benchmark나 Children's Book Test는 거의 완전한 중복을 보여줌에 따라 evaluation에 포함되지 않았다. (Table C.1 참고)
c. 3. Overlap results
몇몇 데이터를 본 것이 downstream task를 수행하는데 얼마나 도움이 되는지를 이해하기 위해서, 모든 validation과 test set을 필터링하였다. 그다음 clean-only example만 가지고 evaluation을 진행하였다. clean score가 original score보다 전반적으로 1-2% 정도 낮았고, 이는 모델이 본 예제에 어느 정도 overfit 되었다는 것을 보여준다. 이 overlap metric은 web에서 가져온 배경지식을 포함하는 dataset(SQuAD)이나 example이 8 단어보다 짧은 경우 높은 비율로 false positive를 보인다.



